Convolutional Encoder Decoder Setup for Speech Recognition
In this post
- Implementing encoder and decoder with causal dilated convolutions. They are a fast alternative to sequential models like RNNs or Transformers.
- Clean implementation of encoder decoder (with attention) architecture with just TF2 / Keras' functional API (no custom layers).
Causal Convolutions
This blog by Kilian Batzner provides excellent explaination and illustrations on this topic.
Here's the main thing to keep in mind.
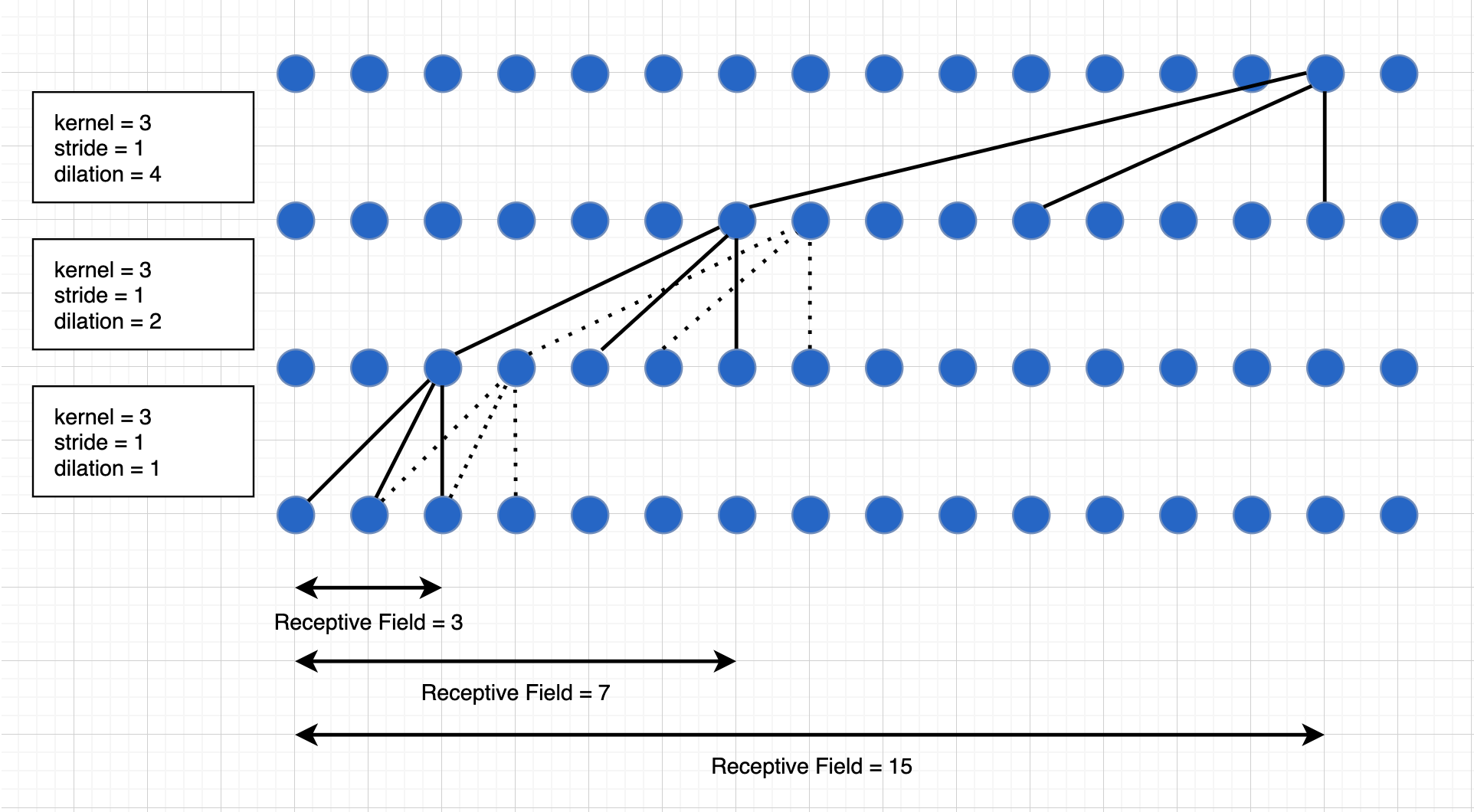 Unlike unidirectional RNNs or Transformer blocks with causal masks, the output at timestep t does not depend on input at every timetsep < t.
There is a receptive field associated with these convolutional layers. Which means, if the recpetive field is 6, output at t only depends on input at
(t-0, ...t-5). Thankfully, the receptive field can be increased easily without dramatically increasing the number of parameters by uisng dilated convolutions.
Unlike unidirectional RNNs or Transformer blocks with causal masks, the output at timestep t does not depend on input at every timetsep < t.
There is a receptive field associated with these convolutional layers. Which means, if the recpetive field is 6, output at t only depends on input at
(t-0, ...t-5). Thankfully, the receptive field can be increased easily without dramatically increasing the number of parameters by uisng dilated convolutions.
For example; If Layer 1,2,3,4... have dilations of 1,2,4,8,... and so on.
- The receptive field with just one layer is 3. (Just the kernel size)
- The receptive field with 2 layers is 7.
- The receptive field with 10 layers is 1031.
However, the number of parameters scales linearly with the number of layers. This results in fast processing over long sequences. Okay, lets get to implementation.
Encoder
The number of layers depends on the receptive field needed to process the input sequence effectively. If each timestep is a word, maybe a receptive field of 20 is enough for a lot of tasks. If each timestep is a character, the recpetive field needs to be bigger. With speech data, huge receptive fields are needed. (eg. 16000 waveform samples in one second of audio)
The code below, shows 5 layers with dilations = 1,2,4,8,16.
def encode_inputs(encoder_inputs):
x_encoder = Convolution1D(256, kernel_size=3, activation="relu", padding="causal")(
encoder_inputs
)
x_encoder = Dropout(0.1)(x_encoder)
x_encoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=2
)(x_encoder)
x_encoder = Dropout(0.1)(x_encoder)
x_encoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=4
)(x_encoder)
x_encoder = Dropout(0.1)(x_encoder)
x_encoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=8
)(x_encoder)
x_encoder = Dropout(0.1)(x_encoder)
x_encoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=16
)(x_encoder)
return x_encoder
Decoder
Two parts in decoder:
A. one that processes past ouputs or targets and returns the hidden state of the decoder till previous timestep
B. one that processes attented encoder outputs and returns prediction at current timestep
def process_past_targets(decoder_inputs):
x_decoder = Convolution1D(256, kernel_size=3, activation="relu", padding="causal")(
decoder_inputs
)
x_decoder = Dropout(0.1)(x_decoder)
x_decoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=2
)(x_decoder)
x_decoder = Dropout(0.1)(x_decoder)
x_decoder = Convolution1D(
256, kernel_size=3, activation="relu", padding="causal", dilation_rate=4
)(x_decoder)
return x_decoder
def decode_attended_input(decoder_combined_context):
decoder_outputs = Convolution1D(64, kernel_size=3, activation="relu", padding="causal")(
decoder_combined_context
)
decoder_outputs = Dropout(0.1)(decoder_outputs)
decoder_outputs = Convolution1D(64, kernel_size=3, activation="relu", padding="causal")(
decoder_outputs
)
# Output
decoder_dense = Dense(num_unique_chars, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs)
return decoder_outputs
Dot Product Attention
- Multiply the output from part A of decoder (above) with the output of encoder at each timestep.
- Apply softmax to the sequence of products to get attention weights (between 0 and 1) for each encoder output.
def attend(x_decoder, x_encoder):
attention = Dot(axes=(2, 2))([x_decoder, x_encoder])
attention = Activation("softmax")(attention)
context = Dot(axes=(2, 1))([attention, x_encoder])
decoder_combined_context = Concatenate(axis=-1)([context, x_decoder])
return decoder_combined_context
Complete model
def create_model():
encoder_inputs = Input(shape=(None, 80), name="enc_inp")
decoder_inputs = Input(shape=(None, num_unique_chars), name="dec_inp")
x_encoder = encode_inputs(encoder_inputs) # encode entire input sequence
x_decoder = process_past_targets(decoder_inputs)
decoder_combined_context = attend(x_decoder, x_encoder) # weighted encoder outputs
# as per processed target tokens from previous timesteps
decoder_outputs = decode_attended_input(decoder_combined_context) # predict targets
# at next timesteps
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer="adam", loss="categorical_crossentropy")
return model
Preprocess speech data
Speech data sets are usually large, and don't fit in memory. So, I've got two options:
- Preprocess on the fly.
Pros: Easy to switch hyperparams. No setup time. No extra disk space needed.
Cons: Slow! GPU won't be in use for a large chunk of training time while the CPU prepares the next batch. - Store processed data on disk.
Pros: Fast! Especially if you use TF Records.
Cons: Can require a lot of setup time and disk space. (About an hour and a half to convert 100 hours of speech to Mel filter banks and save them)
This, however, is the only option if my data doesn't fit in memory and/or I need to completely ustilise TPUs. The only difference with TPUs being that I need to store TF records on a GCP bucket and not my machine. I'll write a separate post about the details later and link it here.
For now, some code to do it on the fly with the with a python generator.
import soundfile as sf
from python_speech_features import logfbank
def pad_waveform(data, maxlen):
padded = np.zeros((maxlen), dtype='float32')
length = len(data)
padded[:length] = data
return padded
def get_feats(audio_file, max_sample_len):
""" returns feats with shape (seq_len, 128) """
data, samplerate = sf.read(audio_file)
data = pad_waveform(data, max_sample_len)
assert samplerate == 16000
feats = logfbank(data, nfilt=128)
return feats
def generator():
while True:
for i, (audio_file, target_text) in enumerate(zip(files, texts)):
encoder_inputs = get_feats(audio_file, max_sample_len)
decoder_inputs = np.zeros((max_target_len, num_unique_chars), dtype='float32')
decoder_targets = np.zeros((max_target_len, num_unique_chars), dtype='float32')
for t, char in enumerate(target_text):
decoder_inputs[t, char_index[char]] = 1.0
if t > 0:
decoder_targets[t - 1, char_index[char]] = 1.0
yield {
"enc_inp": encoder_inputs, "dec_inp": decoder_inputs
}, decoder_targets
Then, create a tf.data.Dataset from generator.
dataset = tf.data.Dataset.from_generator(
generator,
output_types=({"enc_inp": tf.float32, "dec_inp": tf.float32}, tf.float32)
)
Training for speech recognition
batch_size = 64
my_callbacks = [
tf.keras.callbacks.EarlyStopping(patience=3),
tf.keras.callbacks.ModelCheckpoint(
filepath='bigmodel.{epoch:02d}-{val_loss:.2f}.h5',
save_best_only=True,
restore_best_weights=True
)
]
train_dataset = (
train_dataset
.repeat()
.batch(batch_size)
.prefetch(tf.data.experimental.AUTOTUNE)
)
test_dataset = (
test_dataset
.repeat()
.batch(batch_size)
.prefetch(tf.data.experimental.AUTOTUNE)
)
steps_per_epoch = len(train_files) // batch_size
validation_steps = len(test_files) // batch_size
history = model.fit(
train_dataset,
validation_data=test_dataset,
validation_steps=validation_steps,
epochs=20,
steps_per_epoch=steps_per_epoch,
callbacks=my_callbacks
)
"""
## Plot loss values
"""
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "val"], loc="upper left")
plt.show()
Inference from checkpoint
model = tf.keras.models.load_model('bigmodel.16-0.03.h5')
def create_inference_dataset(files):
enc_inp = []
dec_inp = []
for i, audio_file in enumerate(files):
encoder_inputs = get_feats(audio_file, max_sample_len)
decoder_inputs = np.zeros((max_target_len, num_unique_chars), dtype='float32')
decoder_inputs[0, char_index['\t']] = 1.0
enc_inp.append(encoder_inputs)
dec_inp.append(decoder_inputs)
return np.stack(enc_inp), np.stack(dec_inp)
def show_predictions(model, files, targets=None):
in_encoder, in_decoder = create_inference_dataset(files)
predict = np.zeros((test_samples, max_target_len),dtype='float32')
for i in range(max_target_len - 1):
predict = model.predict([in_encoder, in_decoder])
predict = predict.argmax(axis=-1)
predict_ = predict[:, i].ravel().tolist()
for j, x in enumerate(predict_):
in_decoder[j, i + 1, x] = 1
reverse_char_index = dict((i, char) for char, i in char_index.items())
for seq_index in range(test_samples):
# Take one sequence (part of the training set)
# for trying out decoding.
output_seq = predict[seq_index, :].ravel().tolist()
decoded = []
for x in output_seq:
if reverse_char_index[x] == "\n":
break
else:
decoded.append(reverse_char_index[x])
decoded_sentence = "".join(decoded)
print('-')
print('Decoded sentence:', decoded_sentence)
if targets:
print('Target sentence:', targets[seq_index].strip())
test_samples = 10
show_predictions(model, test_files[:test_samples], test_texts)